
之前做技术分享的同学已经介绍过Raft共识算法了,关于算法的概述以及MIT6.824 2A的实现方法可以看他的博客Raft共识算法&MIT6.824 lab2A (jiuyou2020.cn),这里就不过多赘述了。本文主要涉及的是详解一下领导者选举的流程以及Raft算法是如何进行日志复制的。
领导者选举
- Leader:正常情况下,每个集群只有一个Leader。负责处理客户端的写请求、日志复制、向Follower定期发送心跳信息。也就是说,数据是从 Leader向其他节点单向流动的。
- Candidate:Candidate节点向其他节点发送请求投票的RPC消息,如果赢得了大多数选票,就成为 Leader。
- Follower:Follower是被动的,正常情况下不会主动发出请求;当超过一定时间没有收到来自Leader的心跳信息,就会time out,成为Candidate。
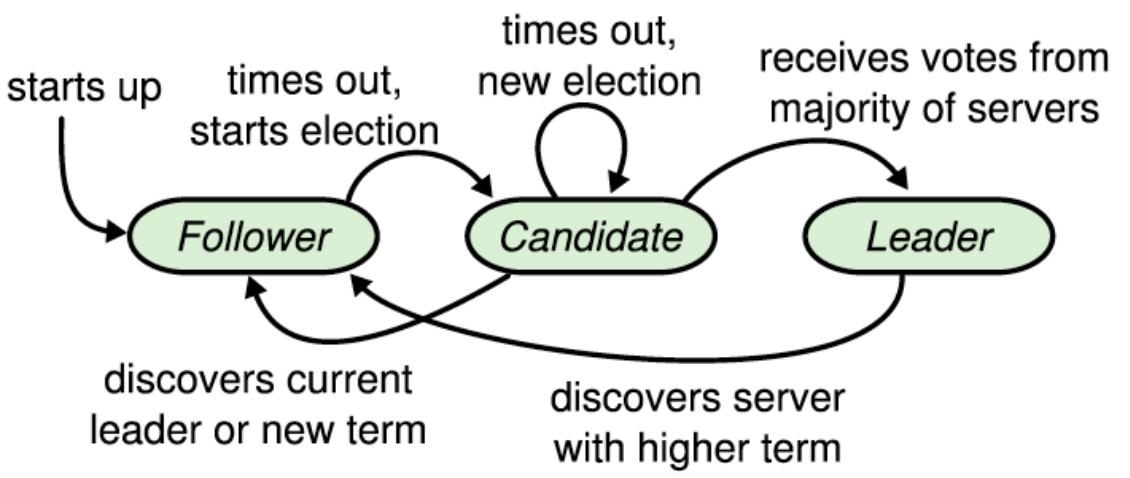
想要了解raft领导者选举的具体过程,有几个重要的概念需要知道
任期
Raft将集群时间划分为一个个连续的任期(Term)。每个任期内只选举一个leader,当该leader节点发生故障之后,其他节点会在新的任期内选举出新的leader,该leader的任期在之前的leader基础上加一。
Raft系统中,任期是一个及其重要的概念,每个节点都维护着当前任期的值,每次节点间的通信都包含任期信息,每个节点在检测到自己的任期值低于其他节点,都会更新自己的任期值,设置为检测到的较高的值。当Leader和Candidate发现自己的任期低于别的节点,则立即把自己转换为Follower。
选举流程
- 所有的节点初始状态都是follower,并被设定一个超时时间。每当超过这个选举时间,follower就会转变为candidate进行选举。Raft算法将每个节点的超时时间设为随机值(在一定范围内),尽可能保证同一时间不会有多个follewer进行选举。这个超时时间会被由leader发出的心跳重置,当follower长时间接收不到节点时,就会重复选举过程。
- 在follower变成candidate之后,要完成如下事件
- 增加自己的任期数
- 启动一个新的计时器
- 给自己投一票
- 向所有其他节点发送RequestVote RPC请求,并等待其他节点回复
- 如果在计时器超时前接收到多数节点(超过半数)的同意投票,则转换为Leader。如果接受到其他节点的AppendEntries心跳RPC,说明其他节点已经被选为Leader, 则转换为Follower。如果计时器超时的时候还没有接受到以上两种信息中的任何一种,则重复步骤1-4,进行新的选举。
- 节点在接受到多数节点的投票成为Leader后,会立即向所有节点发送AppendEntries 心跳RPC。所有Candidate收到心跳RPC后,转换为Follower,选举结束。
- 每个Follower在一个任期内只能投一票,采取先到先得的策略。每个Follower有一个计时器,在计时器超时时仍然没有接受到来自Leader的心跳RPC, 则转换为Candidate, 开始请求投票。也就是在当期Leader当掉后,就会有Follower开始转换为Candidate开始投票。
可以通过这个网站来模拟这个过程Raft Consensus Algorithm
日志复制
日志组成
type Log struct {
LogTerm int
LogIndex int
Cmd interface{}
}Log由任期号,Log索引号以及具体的操作内容组成。
具体过程
在一个节点选举成功成为leader之后,它就可以收到服务器的请求,leader将服务器的请求作为新的内容添加到日志中。任期号为当前Leader所处的任期号,索引号为当前Leader本地存储的日志集合中的日志的最高索引号加1。
之后,leader将日志复制的请求同心跳发送给其他节点(follower)。在收到大部分follower的复制成功的消息后,leader将该日志提交,具体过程分为三步。
- 将改日志在本地磁盘持久化
- 向其他所有的follower发送消息,令其他所有的follower将该日志持久化
- 返回结果到客户端
在此过程中,若有的follower没有返回消息,则leader将会重复发送直到成功
依然可以通过这个网站来模拟这个过程Raft Consensus Algorithm
在出现一致性问题时的解决方案
日志不一致的三种情况
网络不可能一直处于正常情况,因为Leader或者某个Follower有可能会崩溃,从而导致日志不能一直保持一致,因此存在以下三种情况:
- Follower缺失当前Leader上存在的日志条目。
- Follower存在当前Leader不存在的日志条目。
- Follower即缺失当前Leader上存在的日志条目,也存在当前Leader不存在的日志条目。
日志不一致的解决方案
Leader通过强迫Follower的日志重复自己的日志来处理不一致之处,这意味着Follower日志中的冲突日志将被Leader日志中的条目覆盖。这个过程如下:
- 首先,Leader找到与Follower最开始日志发生冲突的位置,然后删除掉Follower上所有与Leader发生冲突的日志,最后将自己的日志发送给Follower以解决冲突。需要注意的是:Leader不会删除或覆盖自己本地的日志条目。
- 当发生日志冲突时,Follower将会拒绝由Leader发送的AppendEntries RPC消息,并返回一个响应消息告知Leader日志发生了冲突。
- Leader为每一个Follower维护一个nextIndex值。该值用于确定需要发送给该Follower的下一条日志的位置索引。该值在当前服务器成功当选Leader后会重置为本地日志的最后一条索引号+1。
- 当Leader了解到日志发生冲突之后,便递减nextIndex值,并重新发送AppendEntries RPC到该Follower,不断重复这个过程,一直到Follower接受该消息。
- 一旦Follower接受了AppendEntries RPC消息,Leader则根据nextIndex值可以确定发生冲突的位置,从而强迫Follower的日志重复自己的日志以解决冲突问题。
Lab2B具体实现
关键代码
Raft定义
type Raft struct {
mu sync.Mutex
peers []*labrpc.ClientEnd
persister *Persister
me int
dead int32
commitIndex int // 局部index,到现在为止,应该被commit的log在leader.log的最高位置
lastApplied int // 局部index,到现在为止,已经被commit的log在leader.log的最高位置
matchIndex []int // 局部index,follower与leader可重合的log,在ledaer的logs中的位置,注意是位置,不是log.index,只有没有snapshot的情况下位置和index才会一样
nextIndex []int // leader下一步要给follower发送的log的index
currentTerm int
votedFor int
role int // server's role: leader, candidate, follower
numServer int // num of all servers
logs []Log
ApplyMsgChan chan ApplyMsg
CommitChan chan struct{} // 如果该通道有消息,则开始提交lastAppliedIndex到CommitIndex之间的log
EndChan chan struct{} // if EndChan get sth, the raft ended
InstallSnapshotChan []chan struct{}
ElectionTimer *time.Timer // timer of ecection
AppendEntriesTimers []*time.Timer // timer of send entry
}Start函数定义
func (rf *Raft) Start(command interface{}) (int, int, bool) {
_, lastLogIndex := rf.GetLastLogTermIndex()
term := rf.currentTerm
index := lastLogIndex + 1
isLeader := (rf.role == leader)
if isLeader {
rf.logs = append(rf.logs, Log{
LogTerm: term,
LogIndex: index, // index是全局index
Cmd: command,
})
rf.matchIndex[rf.me] = len(rf.logs) - 1
rf.persist()
rf.ResetAppendEntryTimers() // 立即向followers发送新的log
}
// 需要返回的index是全局index
return index, term, isLeader
}RequestEntry函数定义
func (rf *Raft) RequestEntry(args *AppendEntries, reply *AppendEntriesReply) {
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
}
snapIndex := rf.lastSnapShotIndex
rf.ChangeRole(follower)
rf.ResetElectionTimer()
LastLogTerm, LastLogIndex := rf.GetLastLogTermIndex()
reply.PeerTerm = rf.currentTerm
reply.PeerLastLogTerm = LastLogTerm
reply.PeerLastLogIndex = LastLogIndex
reply.AppendSuccess = false
reply.MatchIndex = rf.lastSnapShotIndex
if args.Term < rf.currentTerm {
return
}
/*
append失败的两个原因:
1. index没对上,但是term对上了,找index重新写,小改动;
2. term没对上,找term重新写,大改动,需要重新写整个term
*/
// 首先需要考虑一下follower的lastSnapShotIndex
if args.PrevLogIndex < rf.lastSnapShotIndex {
reply.AppendSuccess = false
reply.MatchIndex = rf.lastSnapShotIndex
return
} else if args.PrevLogIndex == rf.lastSnapShotIndex {
if !args.IsHeartBeat {
rf.logs = append(rf.logs[0:args.PrevLogIndex+1-snapIndex], args.Entries...)
rf.persist()
// fmt.Printf("peer %d's logs: %v\n", rf.me, rf.logs)
}
rf.commitIndex = args.LeaderCommit - rf.lastSnapShotIndex
rf.CommitChan <- struct{}{}
reply.AppendSuccess = true
reply.MatchIndex = rf.lastSnapShotIndex + len(args.Entries)
return
}
if args.PrevLogIndex > LastLogIndex {
// 属于index对不上的问题
// 这里是最明显一个的错误,不管是不是同一个term,中间必然存在空块,
// 需要将LastLogIndex作为matchIndex,补上更早的log
reply.AppendSuccess = false
reply.MatchIndex = LastLogIndex
return
}
if args.PrevLogTerm == rf.logs[args.PrevLogIndex-snapIndex].LogTerm {
// 最正常的情况,leader找到follower与自己配对的log,
// 然后把这个log后面的所有日志全部接上自己的,可能有覆盖也可能没有
if !args.IsHeartBeat {
// 如果args包含有要写入的内容,就在这里写入
rf.logs = append(rf.logs[0:args.PrevLogIndex+1-snapIndex], args.Entries...)
rf.persist()
// fmt.Printf("peer %d's logs: %v\n", rf.me, rf.logs)
}
rf.commitIndex = args.LeaderCommit - rf.lastSnapShotIndex
rf.CommitChan <- struct{}{}
reply.AppendSuccess = true
reply.MatchIndex = args.PrevLogIndex + len(args.Entries)
return
}
if args.PrevLogTerm == rf.logs[args.PrevLogIndex-snapIndex].LogTerm {
// args.PrevLog和follower对应位置的log在term上匹配商量,但是idx匹配不上,
// 那就找到follower的上一个term的最后一个index作为matchIndex,
// 把现在这个term全部重新写一遍
idx := args.PrevLogIndex - rf.lastSnapShotIndex // idx是局部index,指在rf.logs中的相对位置
for idx >= rf.commitIndex && rf.logs[idx].LogTerm == rf.currentTerm {
idx--
}
reply.AppendSuccess = false
reply.MatchIndex = idx + rf.lastSnapShotIndex
} else {
// 如果连term都匹配不上,直接从0开始,全部重写
reply.AppendSuccess = false
reply.MatchIndex = rf.lastSnapShotIndex
}
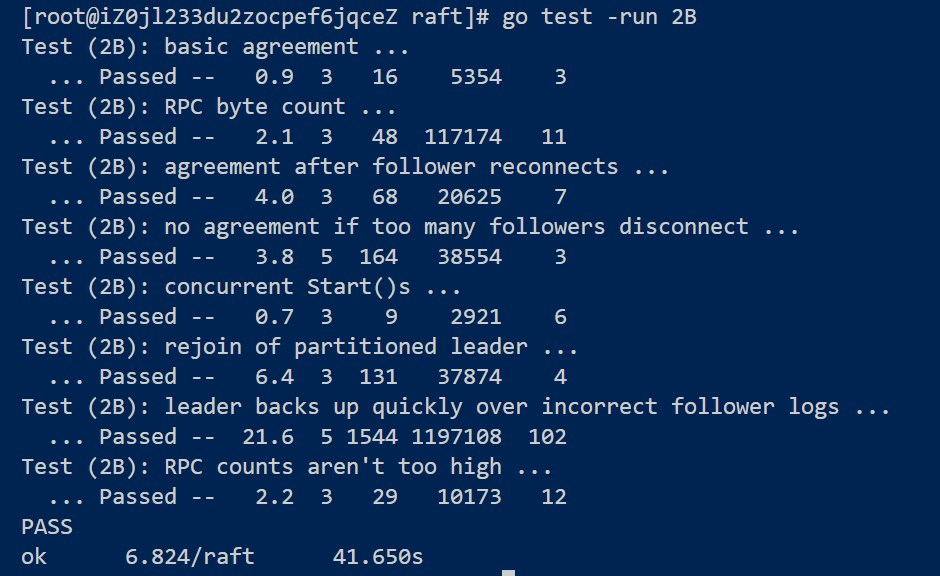
}最终结果
评论区
欢迎你留下宝贵的意见,昵称输入QQ号会显示QQ头像哦~